
Introduction
This project leverages machine learning models to predict diabetes and heart disease using real-world datasets. The aim is to assist in early diagnosis, which can significantly improve patient outcomes by enabling timely interventions. 
- Cholesterol (chol)
- Fasting Blood Sugar (fbs)
- Exercise-Induced Angina (exang)
- ST Depression (oldpeak)
- Slope of Peak Exercise ST Segment (slope)
- Number of Major Vessels Colored by Fluoroscopy (ca)
- Thalassemia (thal)
Modeling Approach
Preprocessing Steps:
- Missing Values: Replaced missing values with feature means.
- Feature Engineering: Applied Polynomial Features (degree 2) to capture non-linear relationships.
- Scaling: Used
StandardScalerto normalize features for both datasets.
Models Used:
- Diabetes Prediction: Logistic Regression with Regularization Parameter (C) = 100, Max Iterations = 2000.
- Heart Disease Prediction: Logistic Regression with Regularization Parameter (C) = 0.01, Max Iterations = 5000, and class weighting to handle imbalance.
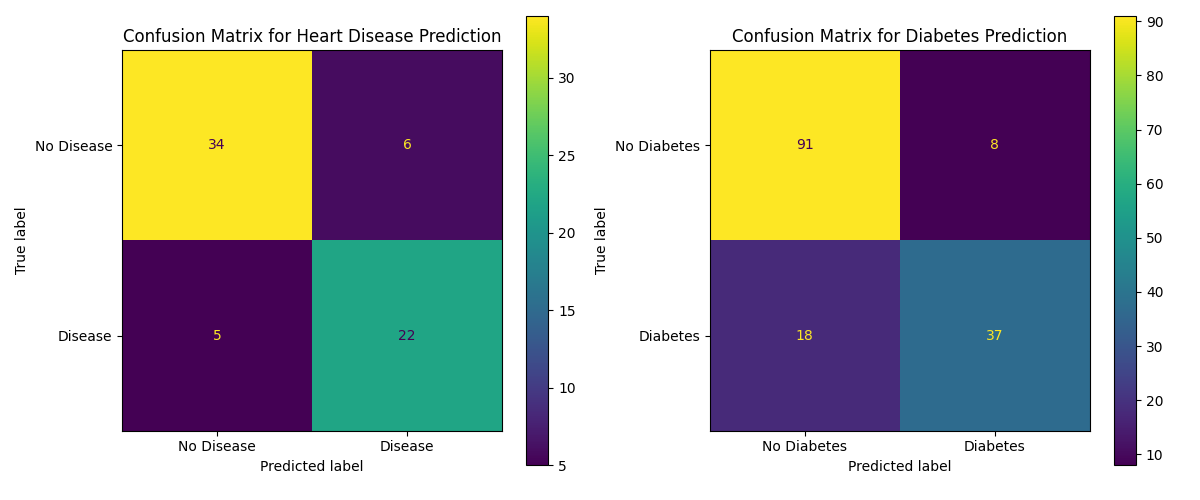
Combined Confusion Matrix:
-
The confusion matrices for both the diabetes and heart disease predictions are shown below:
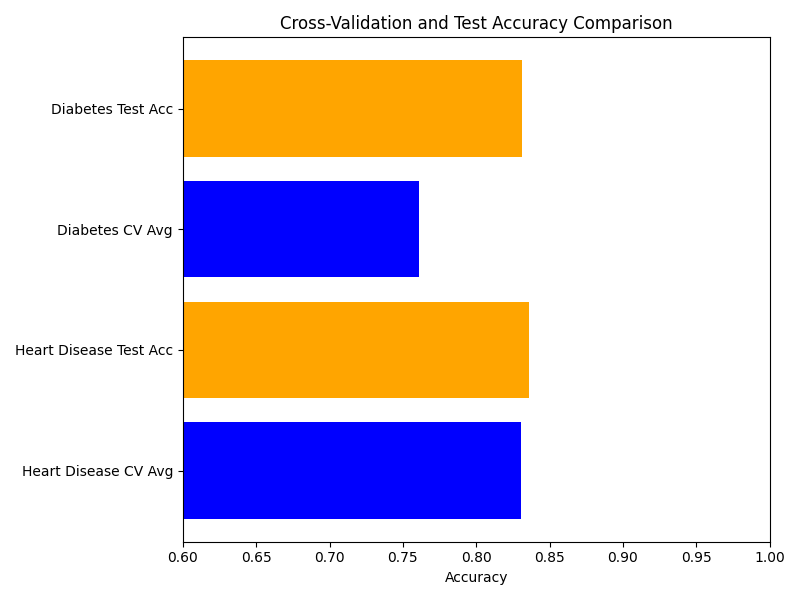
Cross-Validation and Test Accuracy Comparison:
-
The bar chart below shows a comparison of cross-validation and test accuracy for both models:
Challenges and Solutions
Diabetes Prediction:
- Initial Accuracy: Model achieved a training accuracy of 69.4% and validation accuracy of 73.0%.
- Solution: Applied Polynomial Features (degree 2) to improve complexity, resulting in 76.9% training accuracy and 80.8% validation accuracy.
Heart Disease Prediction:
- Multiclass Problem: Initially focused on a multiclass classification approach (no disease, low, medium, high, very high risk) but achieved low cross-validation accuracy (~50%).
- Solution: Converted the task into a binary classification problem and achieved 83.6% test accuracy and 83.0% cross-validation accuracy.
Results
Diabetes Prediction:
- Final Accuracy: Over 80% test accuracy.
- Key Predictors: Glucose levels, BMI.
- Model Improvements: Polynomial features significantly enhanced predictive performance.
Heart Disease Prediction:
- Final Accuracy: Test accuracy of 83.6%.
- Key Predictors: Chest Pain Type, Exercise-Induced Angina, ST Depression (oldpeak).
- Model Insights: Binary classification improved interpretability and accuracy.
Demo
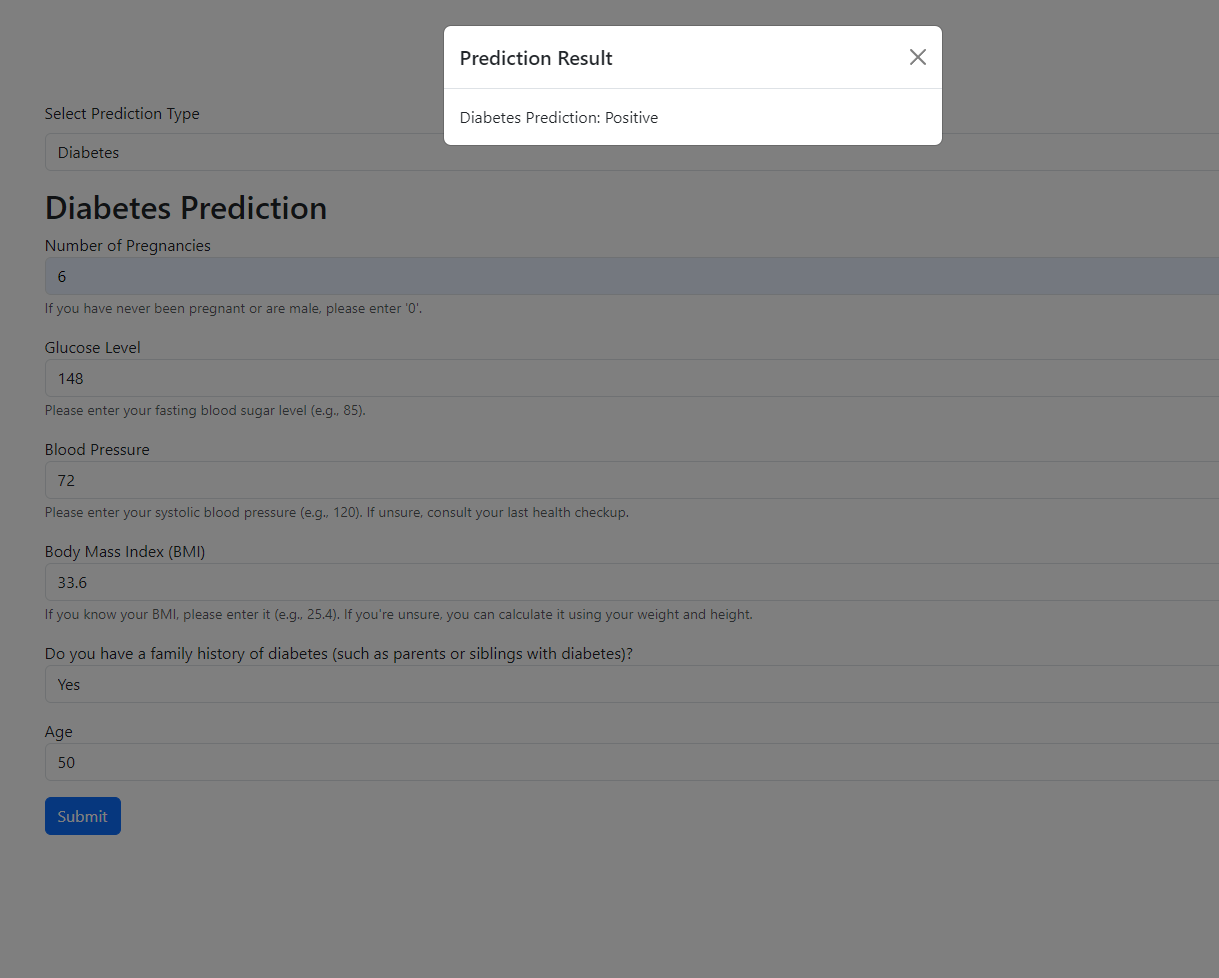
I’ve also created a live demo for this project, which you can check out here. For the full code, detailed instructions, and further exploration, visit the GitHub repository.
Future Improvements
- Larger Datasets: Plan to incorporate larger datasets to enhance model robustness.
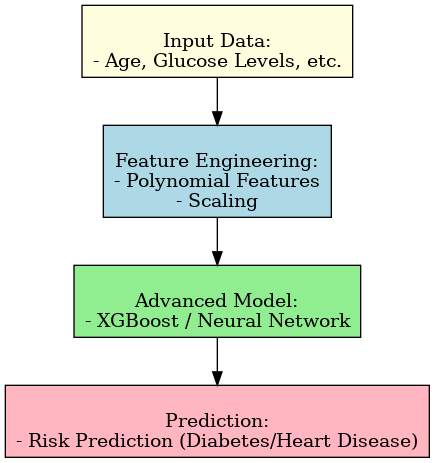
- Advanced Algorithms: Future experimentation with XGBoost or Neural Networks.
- Feature Expansion: Add additional health metrics to improve accuracy further.
Conclusion
This project demonstrates the potential of machine learning in healthcare, specifically in early disease detection. By applying AI models, we can assist healthcare professionals in diagnosing conditions like diabetes and heart disease earlier, potentially saving lives through timely intervention.
Ethical Considerations
This project follows ethical guidelines in handling healthcare data, ensuring patient privacy and addressing biases in the datasets. Future work will involve collaborating with healthcare professionals to validate and improve the model’s real-world effectiveness.